SEO観点におけるURLについて調べていると
URLのクエリパラメータに関するベストプラクティスとして以下の内容が載っていました。
同じパラメータを 2 回使用しないようにします。Googlebot はどちらかの値を無視する可能性があります。
推奨: ?type=candy,sweet
非推奨: ?type=candy&type=sweet (引用)
参考:URL のクエリ パラメータに関するベスト プラクティス
Eccubeで複数選択可の項目を検索すると、 「?type[]=candy&type[]=sweet」 のような、
上記で非推奨とされる「同じパラメータを複数回使用しているURL」になります。
検索エンジンにインデックスさせる対象が、単一選択されたページのみ(「?type[]=candy」「 ?type[]=sweet」 は対象だが 「?type[]=candy&type[]=sweet」 はインデックス対象ではない)
の場合は気にする必要はないと思いますが、もし、複数選択したページをインデックスさせたいなら対応が必要かも(?)ということで今回、Eccube4.3で試してみました。
手順1.複数選択可の検索項目をカスタマイズして追加する
前提条件である「複数選択検索」をできる項目が、Eccube4.3の初期状態では無いので、まずはそれを追加します。
今回は「複数選択可なカテゴリ」を追加します。
(カテゴリ検索は既にあるのですが、単一選択しかできないので、複数選択可な状態のなものを追加します)
1-1.FormTypeのカスタマイズ
EccubeのフォームはFormTypeに実装されているので、カスタマイズして、複数選択可用のカテゴリ項目を追加します。
app/Customize/Form/Extension/ 配下に以下のような「SearchProductTypeExtension.php」を追加します。
実装例
<?php
namespace Customize\Form\Extension;
use Eccube\Form\Type\SearchProductType;
use Eccube\Repository\CategoryRepository;
use Symfony\Bridge\Doctrine\Form\Type\EntityType;
use Symfony\Component\Form\AbstractTypeExtension;
use Symfony\Component\Form\FormBuilderInterface;
class SearchProductTypeExtension extends AbstractTypeExtension
{
private CategoryRepository $categoryRepository;
public function __construct(CategoryRepository $categoryRepository)
{
$this->categoryRepository = $categoryRepository;
}
public static function getExtendedTypes(): iterable
{
yield SearchProductType::class;
}
public function buildForm(FormBuilderInterface $builder, array $options)
{
$categories = $this->categoryRepository->getList(null, true);
$builder->add('category_ids', EntityType::class, [
'class' => 'Eccube\Entity\Category',
'choices' => $categories,
'choice_label' => 'NameWithLevel',
'multiple' => true,
'expanded' => true,
'required' => false,
'label' => 'カテゴリ(複数選択)',
'attr' => [
'class' => 'form-control',
],
]);
}
}これで、既存のSearchProductType に対して、「category_ids」フォーム項目を追加したことになります。
既に存在するカテゴリ検索項目「category_id」との違いは、チェックボックスになるように「’multiple’ => true」「’expanded’ => true」を追加しただけです。
1-2.Repositoryのカスタマイズ
新しく追加したフィールド「’category_ids’」で検索されるようにRepositoryもカスタマイズします。
app/Customize/Repository配下に以下のようなファイルを追加します。
実装例
<?php
namespace Customize\Repository;
use Doctrine\ORM\EntityManagerInterface;
use Doctrine\ORM\QueryBuilder;
use Eccube\Doctrine\Query\QueryCustomizer;
use Eccube\Repository\QueryKey;
class ProductRepositoryCustomizer implements QueryCustomizer
{
private EntityManagerInterface $entityManager;
public function __construct(EntityManagerInterface $entityManager)
{
$this->entityManager = $entityManager;
}
/**
* 商品検索にカテゴリ(複数)を追加する
*
* @param QueryBuilder $builder
* @param array $params
* @param $queryKey
*/
public function customize(QueryBuilder $builder, $params, $queryKey): void
{
// category(s)
if (!empty($params['category_ids'])) {
$Categories = $params['category_ids'];
if ($Categories->count() > 0) {
$subQb = $this->entityManager->createQueryBuilder();
$subQb->select('1')
->from('Eccube\Entity\ProductCategory', 'pct_sub')
->where('pct_sub.Product = p') // 'p'は親クエリのエイリアス
->andWhere($subQb->expr()->in('pct_sub.Category', ':Categories'));
$builder->andWhere($builder->expr()->exists($subQb->getDQL()))
->setParameter('Categories', $Categories);
}
}
}
/**
* ProductRepository::getQueryBuilderBySearchData に適用する.
*
* @return string
* @see \Eccube\Repository\ProductRepository::getQueryBuilderBySearchData()
* @see QueryKey
*/
public function getQueryKey(): string
{
return QueryKey::PRODUCT_SEARCH;
}
}「category_ids」が選択されている場合は、選択されたカテゴリIDが、カテゴリとして設定されている商品をExistで絞り込んでいます。
1-3.twigのカスタマイズ
app/template/default/Product 配下に src/Eccube/Resource/template/default/Product/list.twig のコードをコピーして配置します。するとapp/template/default/Product/list.twig の方が参照されます。
新しく配置したapp/template/default/Product/list.twigのformタグの中に、category_idsフィールドを追加します。
その時、既存の、「FormTypeのフィールドをfor文でhiddenとして書き出している処理」からcategory_idsフィールドを除外します。
実装例
<form name="form1" id="form1" method="get" action="?">
{{% for item in search_form %}
{# category_idsは除外 #}
{% if item.vars.name != 'category_ids' %}
<input type="hidden" id="{{ item.vars.id }}"
name="{{ item.vars.full_name }}"
{% if item.vars.value is not empty %}value="{{ item.vars.value }}" {% endif %}/>
{% endif %}
{{% endfor %}
{{# 新しい複数選択カテゴリフィールドの表示 #}
{<div class="form-group">
{{ form_widget(search_form.category_ids) }}
{{ form_errors(search_form.category_ids) }}
<button type="submit" class="btn btn-primary mt-2">
{{ '検索' }}
</button>
{</div>
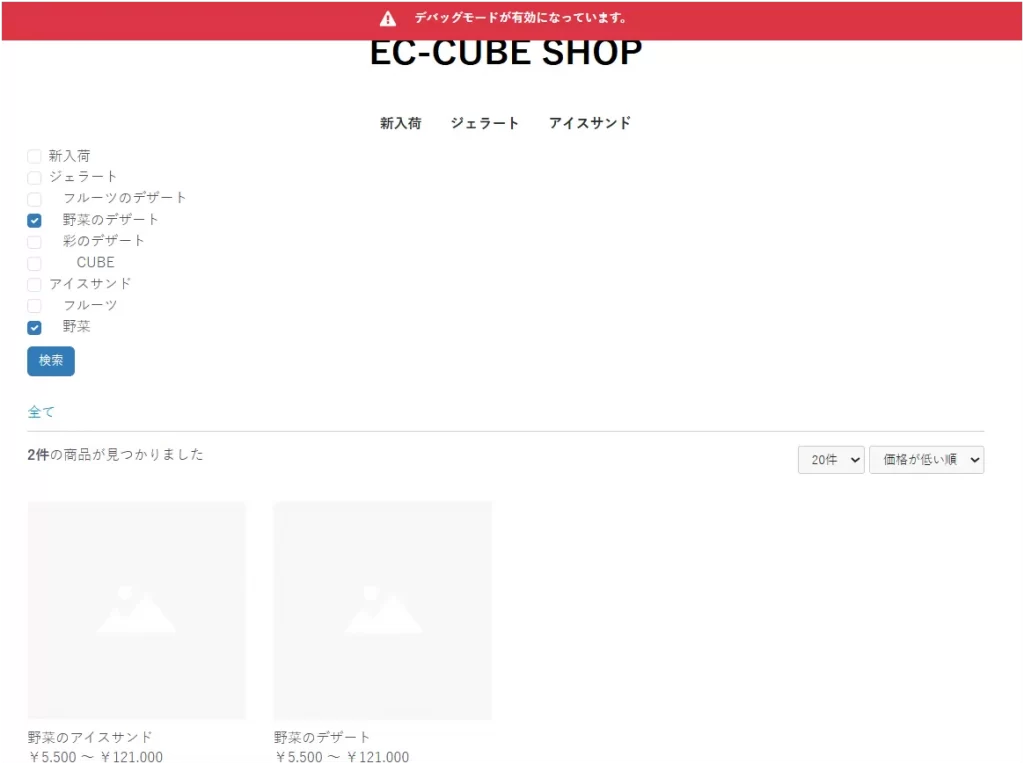
</form>これで検索結果一覧ページにアクセスすると、複数選択出来るカテゴリのチェックボックスと検索ボタンが追加された画面が表示されます。
これでカテゴリの複数検索すると下記のようなURLになります。(デコードしています)
http://localhost:8080/products/list?mode=&category_id=&name=&pageno=&disp_number=20&orderby=1&category_ids[]=7&category_ids[]=9
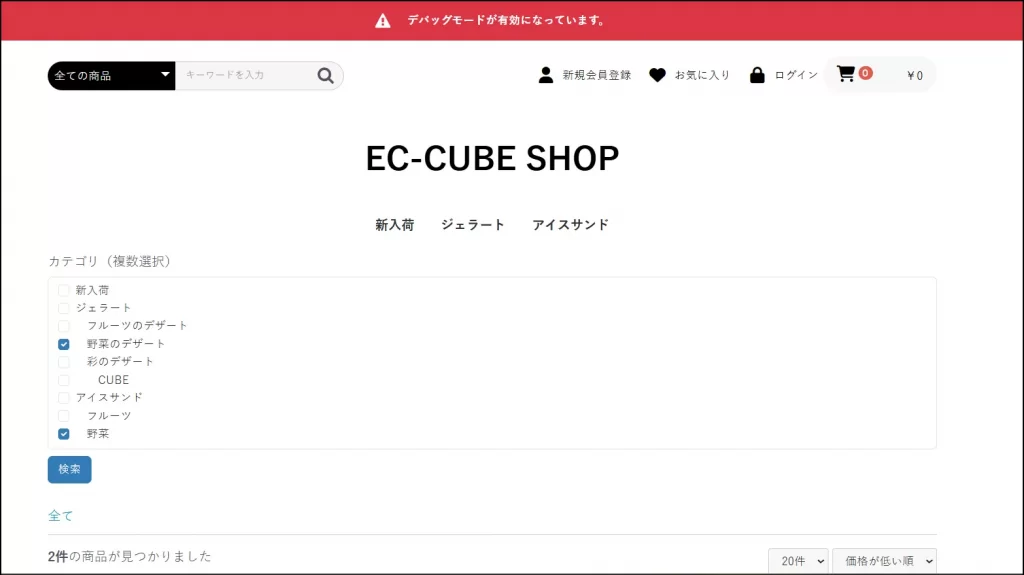
※動作確認のため、いくつかカテゴリを追加しています。
これで前提条件である「同じパラメータを複数回使用したURL」の状態になりました。
手順2.複数カテゴリ検索時のURLをカンマ区切りにする
いよいよ本題であるURLのカンマ区切りに着手します。
2-1.検索実行直前にjavascriptで配列 → 文字列 変更する
チェックボックスで選択した値をそのままの状態で検索実行してしまうと、配列のURLが生成されてしまうので、javascript でカンマ区切りの文字列に変更します。
実装例(app/template/default/Product/list.twig に追記しました)
<script>
document.addEventListener('DOMContentLoaded', function () {
const form = document.getElementById('form1');
form.addEventListener('submit', function (e) {
const checkboxes = form.querySelectorAll('input[name="category_ids[]"]:checked');
const selectedValues = Array.from(checkboxes).map(cb => cb.value);
// 既存の複数inputをdisabledにして送信されないようにする(後で1つのinputにまとめるため)
checkboxes.forEach(cb => cb.disabled = true);
// 新しいhidden inputを1つ作成
const input = document.createElement('input');
input.type = 'hidden';
input.name = 'category_ids';
input.value = selectedValues.join(',');
form.appendChild(input);
});
});
</script>上記のjavascript コードで、以下の内容を実行しています。
- submitの直前に、選択された「category_ids」の値を取得
- 元々の category_idsチェックボックスフィールド はdisabled
- 選択された「category_ids」の値をカンマ区切りにしてformに新フィールドとして追加
これだけでURLは、目的である「同じパラメータは1回しか使用されない」状態になります。
http://localhost:8080/products/list?mode=&category_id=&name=&pageno=&disp_number=20&orderby=1&category_ids=7,9
※デコードしています。
しかし、これだけだと検索がうまくいきません。FormTypeでは配列で送られてくることが期待されていますが、文字列で来たためエラーになってしまいます。
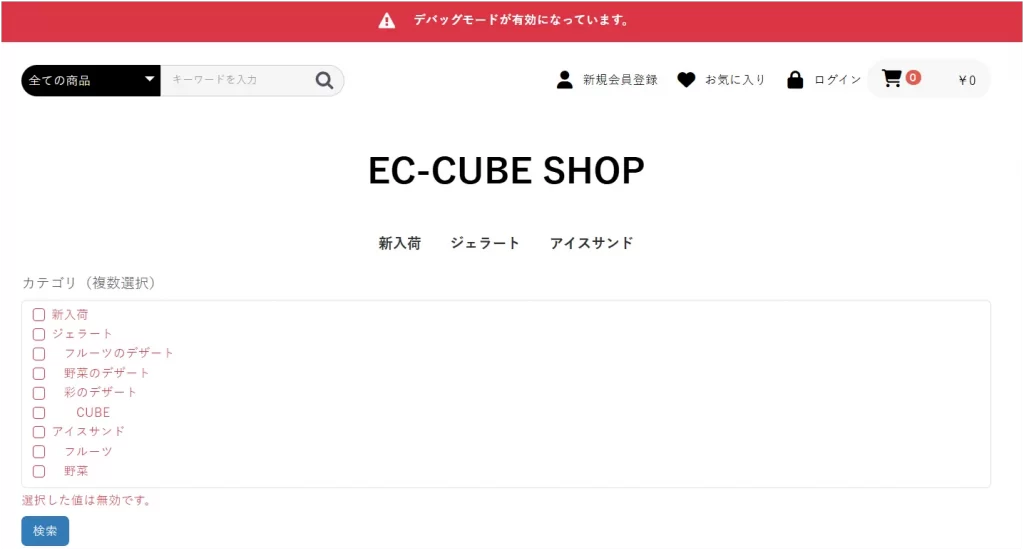
今度はFormType側で文字列 → 配列 に変換して帳尻を合わせます。
2-2.FormTypeの処理時に文字列 → 配列 に変換する
手順1で追加した「SearchProductTypeExtension」に以下の内容を追記します。
実装例
<?php
namespace Customize\Form\Extension;
・・・省略・・・use Symfony\Component\Form\FormEvent; use Symfony\Component\Form\FormEvents;
class SearchProductTypeExtension extends AbstractTypeExtension
{
private CategoryRepository $categoryRepository;
public function __construct(CategoryRepository $categoryRepository)
{ ・・・省略・・・ }
public static function getExtendedTypes(): iterable
{ ・・・省略・・・ }
public function buildForm(FormBuilderInterface $builder, array $options)
{
・・・省略・・・ $builder->addEventListener(FormEvents::PRE_SUBMIT, function (FormEvent $event) { $data = $event->getData(); // カンマ区切りの文字列を配列に変換 if (isset($data['category_ids']) && is_string($data['category_ids'])) { $ids = array_filter(array_map('trim', explode(',', $data['category_ids']))); $data['category_ids'] = $ids; $event->setData($data); } });
}
}PRE_SUBMIT イベントを使って、カンマ区切り文字列を配列に変換しています。
PRE_SUBMIT イベントは「フォームにデータを送信する前に、リクエストのデータを変更する」時に使うものなので、今回のような目的にはピッタリですね。
参考:Symfony Form Events
FormTypeに上記を修正を適用すると、URLの目的を達成しつつ、検索機能も損なわない状態になります。
一応これで今回の試したかったことは出来ました。お試しだったので「category_ids」に特化したコードになってしまいましたが、本当に運用するつもりなら、処理は部品化して汎用的に使えるようにすると良いと思います。
まとめ
いかがだったでしょうか。今回はたまたま見つけた「同じパラメータを 2 回使用しない」を試してみました。
私は今まで聞いたことが無かったので、SEO対策としての重要度はそこまで高く無いのかもしれません。また、最初にも書いた通り、複数選択された状態をインデックスさせる必要が無い場合はそもそも必要ありません。
それなりに対応コストはかかるので、もし本格的に導入を検討をする際には、一度SEO対策会社の方へ相談してから判断するのが良いでしょう。